The Session Journal

Important Security Note
Session journals contain sensitive data such as file contents, commands, API keys, internal discussions, error messages with stack traces, and more.
The .context/journal-site/ and .context/journal-obsidian/
directories MUST be .gitignored.
- DO NOT host your journal publicly.
- DO NOT commit your journal files to version control.
Browse Your Session History¶
ctx's Session Journal turns your AI coding sessions into a browsable,
searchable, and editable archive.
Quick Start¶
After using ctx for a couple of sessions, you can generate a
journal site with:
# Export all sessions to markdown
ctx recall export --all
# Generate and serve the journal site
ctx journal site --serve
Then open http://localhost:8000 to browse your sessions.
What You Get¶
The Session Journal gives you:
- Browsable history: Navigate through all your AI sessions by date
- Full conversations: See every message, tool use, and result
- Token usage: Track how many tokens each session consumed
- Search: Find sessions by content, project, or date
- Dark mode: Easy on the eyes for late-night archaeology
Each session page includes the following sections:
| Section | Content |
|---|---|
| Metadata | Date, time, duration, model, project, git branch |
| Summary | Space for your notes (editable) |
| Tool Usage | Which tools were used and how often |
| Conversation | Full transcript with timestamps |
The Workflow¶
1. Export Sessions¶
# Export all sessions from current project
ctx recall export --all
# Export sessions from all projects
ctx recall export --all --all-projects
# Export a specific session by ID
ctx recall export abc123
# Re-export (updates conversation, preserves YAML frontmatter)
ctx recall export --all
# Full overwrite (discards frontmatter enrichments)
ctx recall export --all --force
Exported sessions go to .context/journal/ as editable Markdown files.
2. Generate the Site¶
# Generate site structure
ctx journal site
# Generate and build static HTML
ctx journal site --build
# Generate and serve locally
ctx journal site --serve
# Custom output directory
ctx journal site --output ~/my-journal
The site is generated in .context/journal-site/ by default.
3. Browse and Search¶
Open http://localhost:8000 after running --serve.
- Use the sidebar to navigate by date
- Use search (
/key) to find specific content - Click any session to see the full conversation
Editing Sessions¶
Exported sessions are plain Markdown in .context/journal/. You can:
- Add summaries: Fill in the
## Summarysection - Add notes: Insert your own commentary anywhere
- Highlight key moments: Use Markdown formatting
- Delete noise: Remove irrelevant tool outputs
After editing, regenerate the site:
Re-Exporting Preserves Your Enrichments
Running ctx recall export --all updates existing files by default:
YAML frontmatter (topics, type, outcome, etc.) is preserved, and only the conversation content is regenerated.
Use --skip-existing to leave existing files completely untouched, or
--force to overwrite everything (frontmatter will be lost).
Large Sessions¶
Sessions with many messages (200+) are automatically split into multiple parts for better browser performance. Navigation links connect the parts:
session-abc123.md (Part 1 of 3)
session-abc123-p2.md (Part 2 of 3)
session-abc123-p3.md (Part 3 of 3)
Suggestion Sessions¶
Claude Code generates "suggestion" sessions for auto-complete prompts. These are separated in the index under a "Suggestions" section to keep your main session list focused.
Enriching Journal Entries¶
Raw exported sessions contain basic metadata (date, time, project) but lack the structured information needed for effective search, filtering, and analysis. Journal enrichment adds semantic metadata that transforms a flat archive into a searchable knowledge base.
Why Enrich?¶
Without enrichment, you have timestamps and raw conversations. With enrichment:
- Find sessions by topic: "Show me all auth-related sessions"
- Filter by outcome: "What did I abandon vs complete?"
- Track technology usage: "When did I last work with PostgreSQL?"
- Identify key files: Jump directly to the files discussed
- Get summaries: Understand what happened without reading transcripts
The Frontmatter Schema¶
Enriched entries begin with YAML frontmatter:
---
title: "Implement caching layer"
date: 2026-01-27
type: feature
outcome: completed
topics:
- caching
- performance
technologies:
- go
- redis
libraries:
- go-redis/redis
key_files:
- internal/cache/redis.go
- internal/cache/memory.go
---
| Field | Required | Description |
|---|---|---|
title |
Yes | Descriptive title (not the session slug) |
date |
Yes | Session date (YYYY-MM-DD) |
type |
Yes | Session type (see below) |
outcome |
Yes | How the session ended (see below) |
topics |
No | Subject areas discussed |
technologies |
No | Languages, databases, frameworks |
libraries |
No | Specific packages or libraries used |
key_files |
No | Important files created or modified |
Type values:
| Type | When to use |
|---|---|
feature |
Building new functionality |
bugfix |
Fixing broken behavior |
refactor |
Restructuring without behavior change |
exploration |
Research, learning, experimentation |
debugging |
Investigating issues |
documentation |
Writing docs, comments, README |
Outcome values:
| Outcome | Meaning |
|---|---|
completed |
Goal achieved |
partial |
Some progress, work continues |
abandoned |
Stopped pursuing this approach |
blocked |
Waiting on external dependency |
Using /ctx-journal-enrich¶
The /ctx-journal-enrich skill automates enrichment by analyzing conversation
content and proposing metadata.
Invoke by session identifier:
/ctx-journal-enrich twinkly-stirring-kettle
/ctx-journal-enrich twinkly
/ctx-journal-enrich 2026-01-24
/ctx-journal-enrich 76fe2ab9
The skill will:
- Find the matching journal file
- Read and analyze the conversation
- Propose frontmatter (type, topics, outcome, technologies)
- Generate a 2-3 sentence summary
- Extract decisions, learnings, and tasks mentioned
- Show a diff and ask for confirmation before writing
Before and After¶
Before enrichment:
# twinkly-stirring-kettle
**ID**: abc123-def456
**Date**: 2026-01-24
**Time**: 14:30:00
...
## Summary
[Add your summary of this session]
## Conversation
...
After enrichment:
---
title: "Add Redis caching to API endpoints"
date: 2026-01-24
type: feature
outcome: completed
topics:
- caching
- api-performance
technologies:
- go
- redis
key_files:
- internal/api/middleware/cache.go
- internal/cache/redis.go
---
# twinkly-stirring-kettle
**ID**: abc123-def456
**Date**: 2026-01-24
**Time**: 14:30:00
...
## Summary
Implemented Redis-based caching middleware for frequently accessed API endpoints.
Added cache invalidation on writes and configurable TTL per route. Reduced
the average response time from 200ms to 15ms for cached routes.
## Decisions
* Used Redis over in-memory cache for horizontal scaling
* Chose per-route TTL configuration over global setting
## Learnings
* Redis WATCH command prevents race conditions during cache invalidation
## Conversation
...
Enrichment and Site Generation¶
The journal site generator uses enriched metadata for better organization:
- Titles appear in navigation instead of slugs
- Summaries provide context in the index
- Topics enable filtering (when using search)
- Types allow grouping by work category
Future improvements will add topic-based navigation and outcome filtering to the generated site.
Batch Enrichment¶
To enrich multiple sessions, process them one at a time:
# List unenriched sessions (those without frontmatter)
grep -L "^---$" .context/journal/*.md | head -10
Then run /ctx-journal-enrich on each. Enrichment is intentionally interactive
to ensure accuracy.
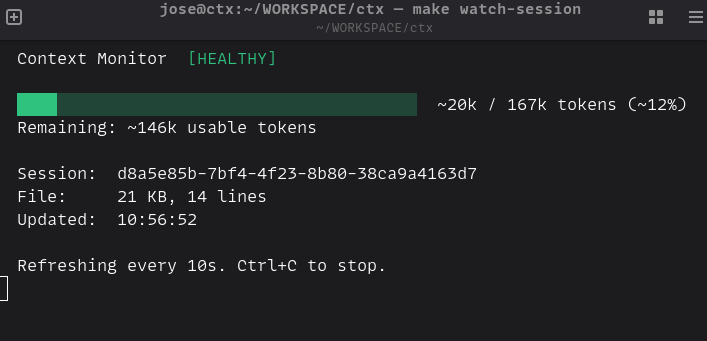
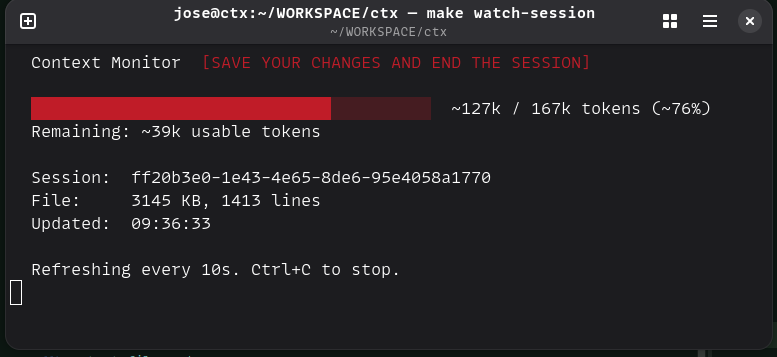
Context Monitor¶
The Context Monitor (context-watch.sh) is a terminal-based tool that shows
real-time token usage for your active Claude Code session. Run it in a separate
terminal window to keep an eye on context consumption.
Setup¶
After running ctx init, the monitor script is available at:
Usage¶
# Default: refresh every 10 seconds
.context/tools/context-watch.sh
# Custom refresh interval (5 seconds)
.context/tools/context-watch.sh 5
The monitor displays:
- Progress bar with estimated token usage versus effective limit
- Color-coded status: green (healthy), yellow (monitor), red (save and end)
- Session info: file size, message count, last update time
- Remaining tokens: how much usable context is left
How It Works¶
The monitor finds the most recently modified session JSONL in
~/.claude/projects/, estimates token count using a character-based heuristic
(~30 chars per token for JSON content), and adds an overhead estimate for system
prompts, tools, and skills that aren't in the JSONL.
| Constant | Value | Meaning |
|---|---|---|
| Model limit | 200,000 | Claude's context window |
| Autocompact buffer | 33,000 | Reserved by Claude Code, not usable |
| System overhead | 20,000 | System prompt + tools + skills + memory |
| Effective limit | 167,000 | What you can actually use for conversation |
Pair with the context checkpoint hook
The monitor is for manual observation. For automated alerts within
your session, the ctx plugin includes a check-context-size hook that
triggers the /ctx-context-monitor skill at adaptive intervals.
Obsidian Vault Export¶
If you use Obsidian for knowledge management, you can export your journal as an Obsidian vault instead of (or alongside) the static site:
This generates a vault in .context/journal-obsidian/ with:
- Wikilinks (
[[target|display]]) instead of Markdown links - MOC pages (Map of Content) for topics, key files, and session types
- Related sessions footer per entry — links to entries sharing the same topics
- Transformed frontmatter —
topicsrenamed totags(Obsidian-recognized),aliasesadded from title for search - Graph-optimized structure — MOC hubs + cross-linked entries create dense graph connectivity
To use: open the output directory in Obsidian ("Open folder as vault").
Static site vs Obsidian vault
Use ctx journal site when you want a web-browsable archive with search
and dark mode. Use ctx journal obsidian when you want graph view,
backlinks, and tag-based navigation inside Obsidian. Both use the
same enriched source entries — you can generate both.
Full Pipeline¶
The complete journal workflow has four stages. Each is idempotent — safe to re-run, and stages skip already-processed entries.
| Stage | Command / Skill | What it does | Skips if |
|---|---|---|---|
| Export | ctx recall export --all |
Converts session JSONL to Markdown | --skip-existing flag |
| Normalize | /ctx-journal-normalize |
Fixes fence nesting and metadata tables | <!-- normalized --> marker |
| Enrich | /ctx-journal-enrich |
Adds frontmatter, summaries, topics | Frontmatter already present |
| Rebuild | ctx journal site --build |
Generates static HTML site | — |
| Obsidian | ctx journal obsidian |
Generates Obsidian vault with wikilinks | — |
Using make journal¶
If your project includes Makefile.ctx (deployed by ctx init), the first
and last stages are combined:
After it runs, it reminds you to normalize and enrich in Claude Code:
Next steps (in Claude Code):
1. /ctx-journal-normalize — fix markdown rendering (skips already normalized)
2. /ctx-journal-enrich — add metadata per entry (skips if frontmatter exists)
Then re-run: make journal
Normalizing Journal Entries¶
Raw exported sessions may have rendering issues: nested code fences,
malformed metadata blocks, or broken lists. The /ctx-journal-normalize
skill fixes these in the source files so the site renders correctly.
It backs up .context/journal/ before modifying anything, and marks processed
files with <!-- normalized: YYYY-MM-DD --> so re-runs skip them.
Run normalize before enrich — the enrichment skill reads conversation content, and clean markdown produces better metadata extraction.
Tips¶
Daily workflow:
# Export, browse, then enrich in Claude Code
make journal && make journal-serve
# Then in Claude Code: /ctx-journal-enrich <session>
After a productive session:
# Export just that session and add notes
ctx recall export <session-id>
# Edit .context/journal/<session>.md
# Regenerate: ctx journal site
Searching across all sessions:
Requirements¶
The journal site uses zensical for static site generation:
Use pipx for zensical
pip install zensical may install a non-functional stub on
system Python 3.9.
Use pipx install zensical instead, which creates an
isolated environment and handles Python version management automatically.
This issue especially happens on Mac OSX.
See Also¶
ctx recall: Session discovery and listingctx journal site: Static site generationctx journal obsidian: Obsidian vault export- Context Files: The
.context/directory structure